



优必选AI研究成果再获国际顶级学术会议认可
近日,第32届人工智能顶级会议AAAI 2018在美国新奥尔良成功召开。作为全球人工智能领域最顶尖的国际学术会议之一,AAAI 是AI学术泰斗讨论和发布学术成果的主阵地,其录用论文反映了国际人工智能领域研究成果的最高水平。在今年的AAAI上,优必选悉尼AI研究院再传捷报,共有5篇论文入选。
此外,国际计算机视觉领域最具影响力、研究内容最全面的顶级学术会议 CVPR也在最近公布了2018年收录论文名单,优必选悉尼AI研究院同样有论文入选。CVPR一向以严苛的录用标准著称,论文录用率一般在20%左右。2018年总投稿量达4000多篇,最终录取了900多篇,录取率不到23%。今年在CVPR上共发表4篇论文,优必选在人工智能领域的研究成果再次得到了国际顶级学术会议的认可。
AAAI 2018
论文一
Domain Generalization via Conditional Invariant Representation
为了将从源域的数据里学习到的模型泛化到将来的某个目标域,我们的方法希望学习到域不变的特征。以前的域自适应方法都是通过匹配特征的边缘分布P(X)来学习域不变特征,但是这种方法假设P(Y|X) 在不同的域稳定不变,现实情况很难保证。我们提出通过匹配条件概率P(X|Y) 并同时衡量P(Y)的变化来保证不同域之间的联合分布P(X,Y)相同。条件域不变特征通过两个损失函数进行学习,一个衡量以类为条件的分布差异,一个衡量以类别归一化的边缘概率分布的差异,从而达到匹配联合分布的效果。如果目标域的P(Y)变化不大,那么我们可以保证得到很好的匹配目标域的特征。
论文二
Adversarial Learning of Portable Student Networks
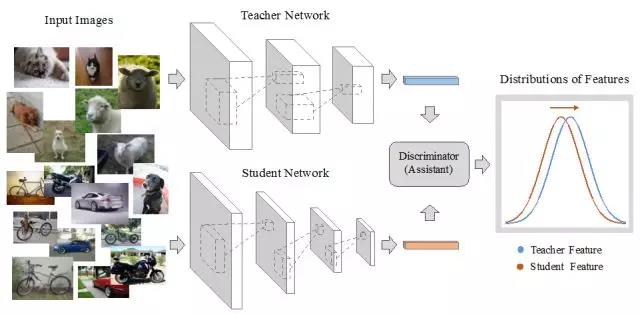
学习具有较少参数的深度神经网络的方法是迫切需要的,因为重型神经网络的庞大的存储和计算需求在很大程度上阻止了它们在移动设备上的广泛使用。与直接去除权值或卷积核以获得比较大的压缩比和加速比的算法相比,使用教师网络-学生网络学习框架的模式来训练轻型网络是一种更灵活的方法。然而,在实际应用中,我们很难确定利用哪一种度量方式来从教师网络中选择有用的信息。为了克服这一挑战,我们提出利用生成对抗网络来学习轻型的学生神经网络,具体地,生成器网络就是一个具有非常少权值参数的学生神经网络,判别器网络被当作一个助教,用来区分学生神经网络和教师神经网络所生成的特征。通过同时地优化生成器网络和判别器网络,本文生成的学生神经网络可以对输入数据生成具有跟教师神经网络特征具有同样分布的特征。
论文三
Reinforced Multi-label Image Classification by Exploring Curriculum
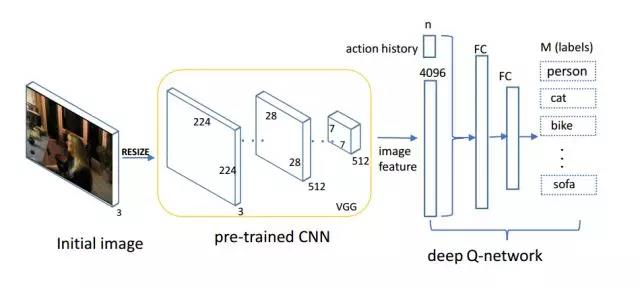
人和动物学习经过组织的知识比学习杂乱的知识更为高效。基于课程学习的机制,我们提出了一种强化多标签分类的方法来模拟人类从易到难预测标签的过程。 这种方法让一个强化学习的智能体根据图像的特征和已预测的标签有顺序地进行标签预测。进而,它通过寻求一种使累计奖赏达到最大的方法来获得最优策略,从而使得多标签图像分类的准确性最高。我们在PASCAL VOC2007 和PASCAL VOC2012 数据集上的实验表明了,在真实的多标签任务中,这种强化多标签图像分类方法的必要性和有效性。
论文四
Learning with Single-Teacher Multi-Student
本文研究了如何通过一个单一的复杂通用模型来学习一系列的轻量专用模型,即单老师多学生(Single-Teacher Multi-Student)问题。以经典的多分类和二分类为例,本文围绕着如何利用一个预训练的多分类模型来衍生出多个二分类模型,其中每个二分类模型对应不同的类别。在实际场景中,许多问题可以被看做这一范畴;例如,基于一个通用的人脸识别系统对于特定的嫌犯进行快速准确地判断。然而,直接使用多分类模型进行二分类操作的推断效率不高,从头训练一个二分类器的分类表现往往不好。本文通过将多分类器看做老师,将目标的二分类器看做学生,提出了一种门化支持向量机(gated SVM)模型。此模型中,每一个二分类器可以结合多分类器的推断结果给出自己的预测;此外,每个学生可以获得由老师模型给出的样本复杂度度量,使得训练过程更加自适应化。在实际实验中,所提模型取得了不错的效果。
论文五
Sequence-to-Sequence Learning via Shared Latent Representation

受人脑可以从不同的模态学习和表达同一抽象概念的启发,本文提出了一个通用的星状框架实现序列到序列的学习。该模型中将不同模态的内容(外围节点)编码到共享隐表征(shared latent representation,SLR),即中央节点中。SLR 的模态不变属性可以被视为中间向量的高级正则化,强制它不仅捕获每个单个模态的隐式表示(如自动编码器),而且还可以像映射模型一样进行转换。因此,我们可以从单个或多个模态学习SLR,并且生成相同的(例如句子到句子)或不同的(视频到句子)的模态信息。星型结构将输入与输出分离,为各种序列学习应用提供了一个通用且灵活的框架。此外,SLR 模型是内容相关(content-specific)的,这意味着它只需要对数据集进行一次训练,就可以用于不同的任务。
CVPR 2018
论文一
An Efficient and Provable Approach for Mixture Proportion Estimation Using Linear Independence Assumption
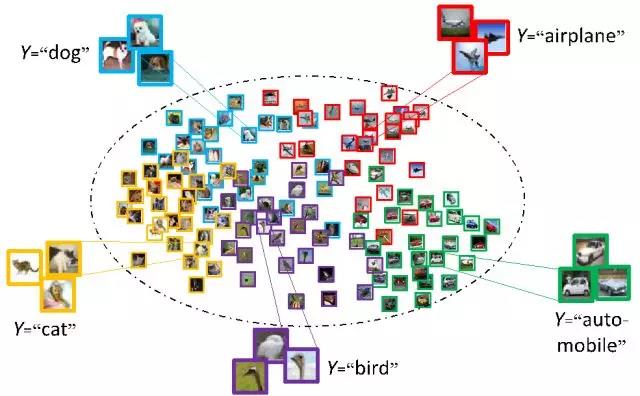
为了研究混合分布中各个组成分别的比例系数,假设各个组成分布满足线性独立的假设(即不存在一种组合系数,使得这些组成分布的线性组合所得到的分布函数处处为0),并且假设每个组成分布中都可以采样到少量的数据。首先论证了组成分布线性独立(组成分布不相同即可)的假设要弱于现有的估计其比例方法的各种假设。其次,提出先将各个分布嵌入到再生核Hilbert空间,再利用最大平均差异的方法求取各组成分布的比例系数。该方法能够
(1)保证比例系数的唯一性和可识别性;(2)保证估计的比例系数能够收敛到最优解,而且收敛率不依赖于数据本身;
(3) 通过求解一个简单的二次规划问题来快速获取比例系数。这项研究拥有广泛的应用背景,比如含有噪声标签的学习,半监督学习等等。
论文二
Deep Ordinal Regression Network for Monocular Depth Estimation

在3D视觉感知主题里,单目图像深度估计是一个重要并且艰难的任务。虽然目前的方法已经取得了一些不错的成绩,但是这些方法普遍忽略了深度间固有的有序关系。针对这一问题,我们提出在模型中引入排序机制来帮助更准确地估计图像的深度信息。具体来说,我们首先将真值深度(ground-truth depth)按照区间递增的方法预分为许多深度子区间;然后设计了一个像素到像素的有序回归(ordinal regression)损失函数来模拟这些深度子区间的有序关系。在网络结构方面,不同于传统的编码解码 (encoder-decoder)深度估计网络, 我们采用洞卷积 (dilated convolution)型网络来更好地提取多尺度特征和获取高分辨率深度图。另外,我们借鉴全局池化和全连接操作,提出了一个有效的全局信息学习器。我们的方法在KITTI,NYUV2和Make3D三个数据集上都实现了当前最佳的结果。并且在KITTI新开的测试服务器上取得了比官方baseline高出30%~70%的分数。
论文三
Self-Supervised Adversarial Hashing Networks for Cross-Modal Retrieval
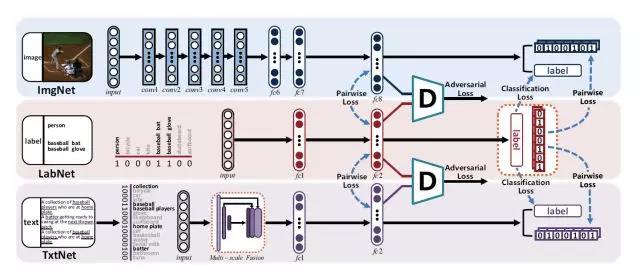
由于深度学习的成功,最近跨模态检索获得了显著发展。但是,仍然存在一个关键的瓶颈,即如何缩小多模态之间的模态差异,进一步提高检索精度。本文提出了一种自我监督对抗哈希(SSAH)方法。这种将对抗学习以自我监督的方式引入跨模态哈希研究,目前还处于研究早期。这项工作的主要贡献是采用了一组对抗网络来最大化不同模态之间的语义相关性和表示一致性。另外,作者还设计了一个自我监督的语义网络,这个网络针对多标签信息进一步挖掘高层语义信息,使用得到的语义信息作为监督来指导不同模态的特征学习过程,以此,模态间的相似关系可以同时在共同语义空间和海明空间两个空间内得以保持,有效地减小了模态之间的差异,进而产生精确的哈希码,提高检索精度。在三个基准数据集上进行的大量实验表明所提出的 SSAH 优于最先进的方法。
论文四
Geometry-Aware Scene Text Detection with Instance Transformation Network
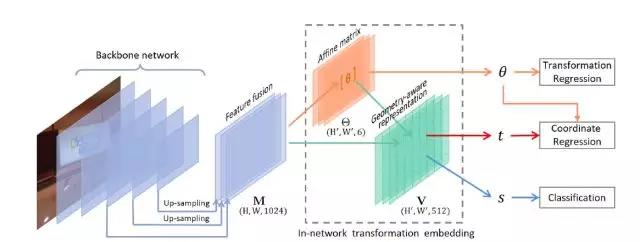
自然场景文字识别由于其文字外形、布局十分多变,是计算机视觉中具有挑战性的问题。在本文中,我们提出了几何感知建模方法(geometry-aware modeling)和端对端学习机制(end-to-end learning scheme)来处理场景文字编码的问题。我们提出了一种新的实例转换网络(instance transformation network),使用网内变换嵌入的方法学习几何感知编码,从而实现一次通过的文本检测。新的实例变换网络采用了转换回归,文本和非文本分类和坐标回归的端对端多任务学习策略。基准数据集上的实验表明了所提方法在多种几何构型下的有效性。
【推荐阅读】

